[まとめ記事] DatabricksのSparkはSnowflakeと競合するか

世界制覇に向けてDatabricksが順調に業績を伸ばしています。そしてシリーズGラウンドで$1Bを調達しました。時価総額は$28Bまで成長したとのことです。(1ドル100円換算で2兆8,000億円)
株式市場では、DatabricksはSnowflakeの競合相手だと評価されています。もともとはSpark OSSの発案者たちが創業したDatabricksですが、衰退するHadoopベンダとは違って躍進中です。
今回はDatabricksの経営手腕と、どうしてSnowflake競合相手と見做されるのかを紹介させて頂くことにします。
(オマケとしてHadoopベンダの戦略ミスなどにも言及しておきます)
Databricksの経営手腕
SparkはUCB(UCバークレー)のAMPLabで考案されたOSSです。ここではApache Mesosなど、幾つもの有力OSSが開発されました。
複数マシンに処理を分散させ、さらにメモリ上にデータを継続保持しながら処理させるためのフレームワークです。こういったプログラムの性質上、何度も処理を繰り返す計算アルゴリズムに向いています。
ただしストレージ上のデータを何もせずに、Spark単体でオンメモリと行き来させるのは一苦労です。Sparkが考案&Apache寄贈された2009年頃は、Apache SparkとMesosを組み合わせて利用する構成が多かったです。
なおMesosはMesosphereという社名で起業しましたけど、SparkはDatabricksという社名で起業しました。Big Dataという流行語が形成されつつあった頃ですけど、製品よりもビジネス内容を優先した社名決定が見事です。
またHadoopが人気を得るとHadoopとの親和性を高め、HadoopとSparkを組み合わせて利用する形態で導入実績を増やしました。そして単にSparkを提供するだけでなく、SQL on Sparkの普及に尽力した点なども流石です。
ただし分散オンメモリで繰り返し処理をするというソフトウェアは、マイナーであることは確かです。そこでDatabricksはHadoopベンダに対して気前よくSpark開発ノウハウを提供して協業し、共同イベントを ”開催して貰って” いました。
さてこの頃のHadoop取り扱いベンダは、Deep Learning分析ソフトウェアのパッケージングに勤しんでいました。そしてApache Hadoop開発者たちは、HDFSよりも大容量オブジェクトストレージソフトウェア開発に勤しんでいました。
このような動きを見ながら、SparkではSpark SQLやSpark ML (Machine Learning)の開発を進めました。それが一段落すると、今度はHadoop HDFSやAWS S3などで構成されるデータレイクを仮想化する “Lakehouseアーキテクチャ” を提唱して来ました。
今では当たり前に感じられる構想や製品かもしれませんけど、他社よりも少しだけ早く状況認識して、すぐさま構想や製品の形にまとめてきました。同じように優秀な人材を抱えながら、少なくともHadoopベンダはHDFS部分に固執して何も手を打たずに、現在は徐々に沈み込んでいます。
ここはClouderaやHortonworks経営陣を責めるよりも、Databricks経営陣を賞賛した方が良さそうです。少なくとも彼らは人気が今一つなSparkでも会社を倒産させることなく、少しずつ業績向上させて来ました。
Snowflake競合
さてDatabricksのLakehouseアーキテクチャは、Delta Lake抽象化レイヤを持っています。(出典ASCII誌)
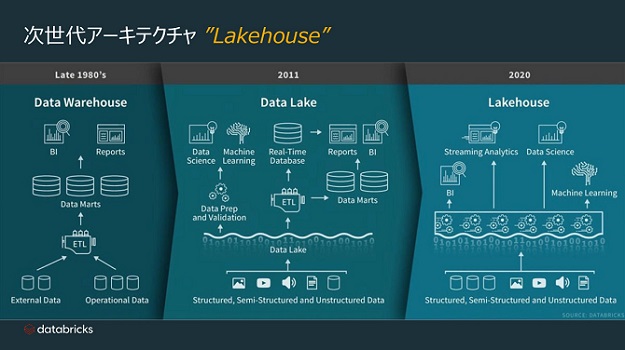
このDelta LakeでHadoop HDFSやAWS S3のデータを収集してからSpark SQLを用いて、Spark処理へと繋げて行きます。(さらにはJava, Pythonなどの実行へも繋げています)

つまりJavaやPythonを使うユーザ(データサイエンティストたち)の立場からすると、Hadoop HDFSやAWS S3のデータを気軽に利用できます。実施できる内容自体は、Snowsflakeと似ています。
もちろんSnowflakeの場合は、FoundationDBで処理データそのものを収集します。そしてユーザはFoundationDBに蓄積されたデータを活用するという構図です。出来ることは似ていても、実現方式は異なります。
ただし証券市場の関係者からすれば、技術的な違いは気になりません。彼らにとって気になるのは、「それで何が出来て、その結果として売上がどのくらい期待できるのか?」です。
だからDatabricksの資金調達には人気が集まり、過熱気味になっているとも言えそうな状況です。それにMicrosoftやSalesforceを始めとして、名だたるIT企業たちも出資しています。無理からぬ話かもしれません。
ちなみにSparkはKubernetes対応することにより、プログラムを実行する時にHadoopを必要としなくなりました。SnowflakeではFoundationDBを採用していますが、SparkではSpark SQLを採用しています。
ここら辺のデータ処理が、Kubernetesシステムとデータ管理の双方に役立っているのかもしれません。ちなみにVMware Tanzu ObservabilityもFoundationDBに管理用データを蓄積しています。
FoundationDBはKey Valueストア型DBをTime SeriesDBとして利用している訳ですが、ITシステムもアプリケーション扱いデータも単一DBで管理するというのが、これからの主流になって行くのかもしれません。(某企業の技術部門のエラい方が、VMware Tanzu Observabilityに強い興味を示していました。その慧眼には脱帽です)
まとめ
以上のように、Databricksは創業直後からイケイケどんどんで急成長した訳ではありません。Sparkという大変に興味深い商材を持ちながらも、それだけに頼ることにない堅実経営によって人員/売上などの経営基盤を強化して来ました。
Snowflakeの競合相手と評価されるポジションを獲得したのは、素人目には見事だとしか映りません。ただし優雅に見える白鳥が水面下で足を全力回転させるように、Databricks幹部もアレコレと試行錯誤しながらビジネスをやっているようです。
ともかく、DatabricksとしてはSpark OSSを開発中止しても、十分にやっていける訳です。昨今はRed HatがCentOSの開発終了を宣言したり、OSS界も相当大変そうです。Spark以外のビジネスが成立するという点では、先輩のRed Hatよりも先行しています。
今後もDatabricksの動向には注意を払っておくのが良さそうです。
それでは今回は、この辺で、ではまた。
———————-
記事作成: よつばせい

